Load Balancing: The power of micro-batching

It’s no secret I am a big fan of the “power of two random choices” algorithm (or more generally best-of-k) for resource based load balancing. I have written several articles about it (such as this one) on why it’s so damn powerful and various ways to improve it further. Today, I want to discuss a very interesting trick you can pull in a high traffic situation to greatly reduce number of samples and improve placement quality using micro-batching.
Micro-batching aka opportunistic-batching aka dynamic-batching is a technique where you find the opportunity to batch things from a stream if they come to you close together in time. If you have a high traffic service, you can often create small micro-batches of requests by just waiting for a few milliseconds. It’s useful if you can more efficiently process the batch of size n instead of n separate requests. One such example is with GPU inferencing. Since GPUs are good at processing large matrices, if you wait a little bit for more inference requests, you can make your request matrix larger by batching these requests together and actually improve the GPU utilization and the average response time for all requests — and still cap the P99 by setting guardrails on how much time to wait for and what’s the largest batch to accept.
Now the question is how does this apply to load balancing to improve best-of-k. Hopefully it’s clear that micro-batching is definitely possible in this situation as workload placement requests come in a stream just like GPU inferencing (in fact, inferencing is an example of a workload that might need load balancing). If they are sufficiently close together in time, you can wait to form small batches. Say we are not greedy and happy with just a batch size of two workloads at a time. In a usual best-of-k setting, we will draw 2*k total random workers independently and choose two of them and throw other 2*k-2 away.
The question is, instead of doing this independently, what if we batched the two workloads together and drew k samples such that k ≥ 2 and choose the two best out of them for our two workloads. Is that better than two independent draws? Let’s take a simple example of when we just draw 2 samples from the pool for a micro-batch of 2 workers. Say we are placing based on memory requirements of the workloads and available memory in the workers (this will extend to multi-dimensional placements as well but let’s just focus on this simple example for now). In that case, as long as both workers aren’t equally filled and both workloads don’t have equal requirements, even though we can’t throw away any workers, we make the fleet a little bit better placed. This is because we will sort workers by their remaining memory and reverse sort workloads by their requirements and do the placement. This can be a *lot* better than random placements as we will see later. Now if we take a sample of three instead of two, we have one worker to throw away which should make it even better.
Simulation
Now to compare, let’s take a fleet of 8000 workers, each with 250GB memory and place 120k workloads on it (if these numbers feel a bit contrived, they are because I wanted a case that’s still kinda bad with k=5 on best-of-k which is not easy). The workload memory in MB is drawn from a gamma distribution between 1 and 50 with k = 5 and theta = 3 similar to this post. As customary, let’s first see how the placements look with just random placements:
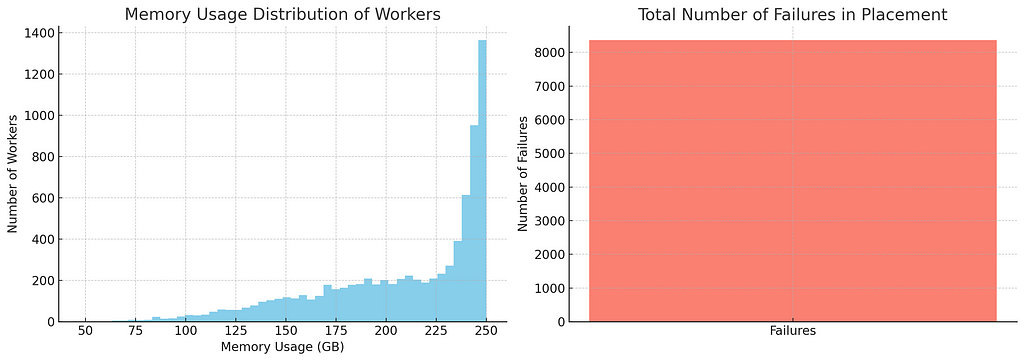
No surprises here. We all know random is bad so let’s try best-of-2. In addition, we will plot number of samples we had to take to do the placements (so for best-of-2, it’ll be 2*120k).
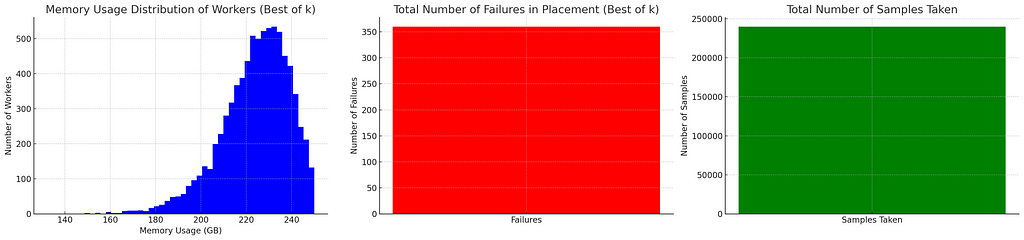
So our failures went down from 8000 to 350 but we had to take 240k samples to achieve that. We know of course that larger k values improve placements so let’s try k=3 and k=5.
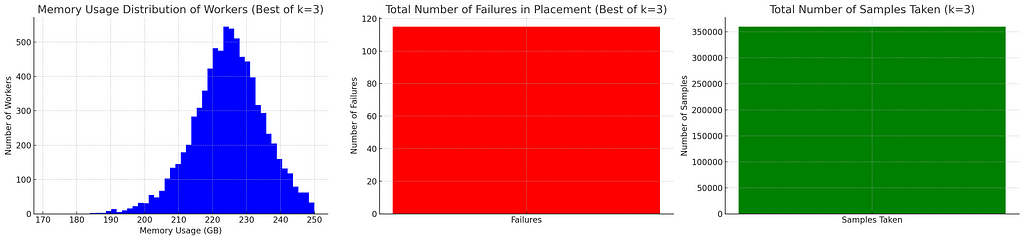
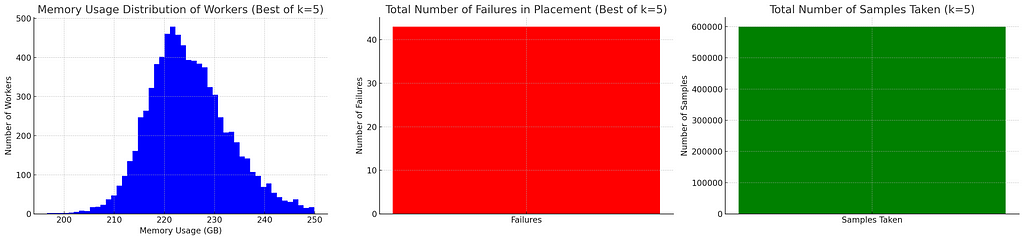
This is actually not great. The placement definitely gets better but the improvement is relatively small for all the extra samples we have to make for samples. K value of 5 need 600k samples!
Now let’s say we can always get a mini-batch of 2 and we will simply take a sample of two workers and choose the emptier one for the larger workload and vice versa. This is more comparable with pure random placements as we can’t discard anything.
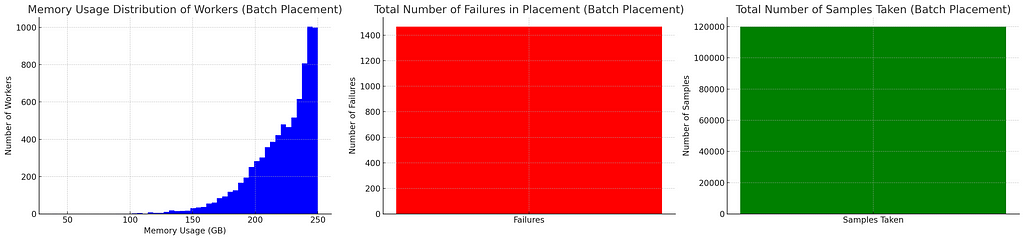
This is actually a lot better than random placements (1400 failures vs 8000 on random) while not as good as best of 2 (320 failures). Let’s use a little more samples and take a sample of 3:
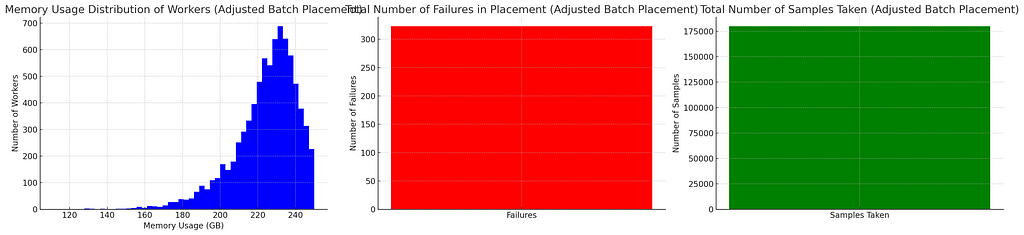
This is already better than best-of-2 with only 2/3rd of samples. If we allow same number of samples as best-of-2 (so a sample of 4):
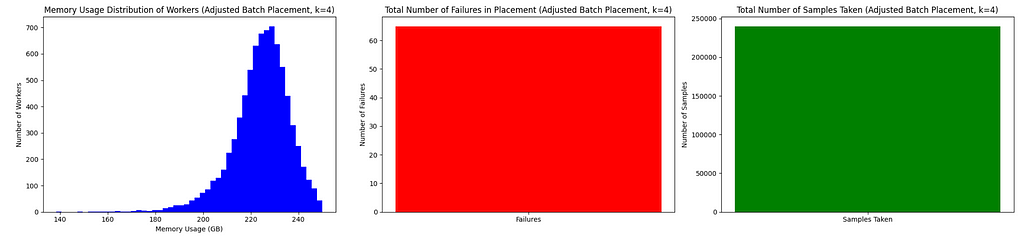
Voila — this is as good as k==5 best-of-k in only 2/5th the number of samples, brought to you by mini-batching!
Bath Sizes
Now the next question is can we do better in fewer comparisons if we can achieve larger batches than 2. Let’s take a moderately large batch of 10 with 18 samples per batch (this is fewer samples than best-of-2):
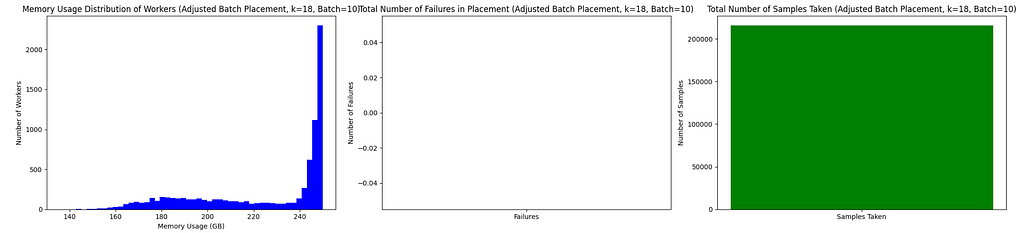
While it may not look visually pretty, this is nearly perfect placement and we get no failures whatsoever in this situation. In general, bigger batches should need you fewer extra workers as the benefit of right sizing among the available fleet kicks in more for larger batches.
More Motivation
If I can get more efficiency in less work, I don’t really need more motivation to buy into a strategy. If you do, here’s something more to consider. With best-of-k, you have to take k samples per workload. If you have large peak times (top of the hour, top of the day etc.), which most real world things do, your sampling workload suddenly scales with your incoming workload requests which can put a lot of stress on your fleet (both on workers and load balancers). Mini-batching kicks in and shines exactly in these times and keeps the total load on the system for load balancing virtually at constant levels. It can even reduce the load although I won’t say that’s something I’d actively seek.
Moreover, fewer concurrent samples have a nice statistical property that gives you more reliable results in a world with multiple stateless load balancers. With lots of samples with large k, you concurrently see the same set of workers in many places and make simultaneous placement decisions against them considering their stale state, causing focus-firing type behavior. With mini-batching, we see and discard a lot fewer workers per draw which makes for less chaotic placements.
Caution on Correlated Workloads
One thing to be careful when batching is correlated workloads. It’s not uncommon for the workloads of similar type showing concurrently at the same time. They tend to have very similar resource usage profile. In this case, if they make the same mini-batch consistently, we lose the power from relative placement on different workers a bit. If for example we sample two workers for a mini-batch of size 2 and the two workloads are identical in their memory usage, we are essentially running random placement. If we take a sample of 4, that’s best-of-2 which is better but not as good as the results we saw above.
In general, you want to make sure your mini-batches have a good level of diversity in resource profile for better results. One approach to achieve this is to assign a discrete classifier to workloads like XS, S, M, L, XL etc. and when batching, trying to pick equally from all these categories if possible — preferring a smaller batch if that gives us a better mix. I will do a followup on a good stratification strategy in the multi-dimensional cases.
Conclusion
Mini-batching is often a powerful optimization technique at large scale that helps get better throughput from your system managing load from the peaks as long as you can figure out how to make your job scale sub-linearly with the batch size. In this article, we saw how to do this with our favorite best-of-k algorithm for resource-based load balancing.
Load Balancing: The power of micro-batching was originally published in The Intuition Project on Medium, where people are continuing the conversation by highlighting and responding to this story.