Cracking the Enigma Code Today

The Enigma Machine is a true icon in the world of cryptography, captivating generations of mathematicians and computer scientists. Developed by the Germans during World War II, even the experts considered this machine impregnable until the ingenious efforts of Alan Turing and his team at Bletchley Park. Turing’s breakthroughs not only helped to save countless lives but also revolutionized the field of computing, paving the way for modern computers as we know them today.
With the power of modern technology at our fingertips, it’s tempting to think that breaking Enigma would be a trivial task. However, as we’ll explore in this blog, this is far from the truth. Despite the advances in computing power, the Enigma Machine remains a formidable challenge. So, join me on a journey through the past and present as we attempt to break Enigma.
This was the first post I ever wrote and funnily enough, something of an enigma for me because it’s my second best performing post in terms of views but I don’t have a good handle on where the readers are coming from, whether they find it useful or is it a search engine glitch that forces them here etc. If you are reading this, please consider leaving a comment on what brought you here and if you find this useful and if you’d like me to write more of this type of content.
- Mihir
This is part I of a two-part post. In this post, we will understand the problem and build an intuition for a solution and in the next one, we will actually code-up some solutions.
Understanding the Machine
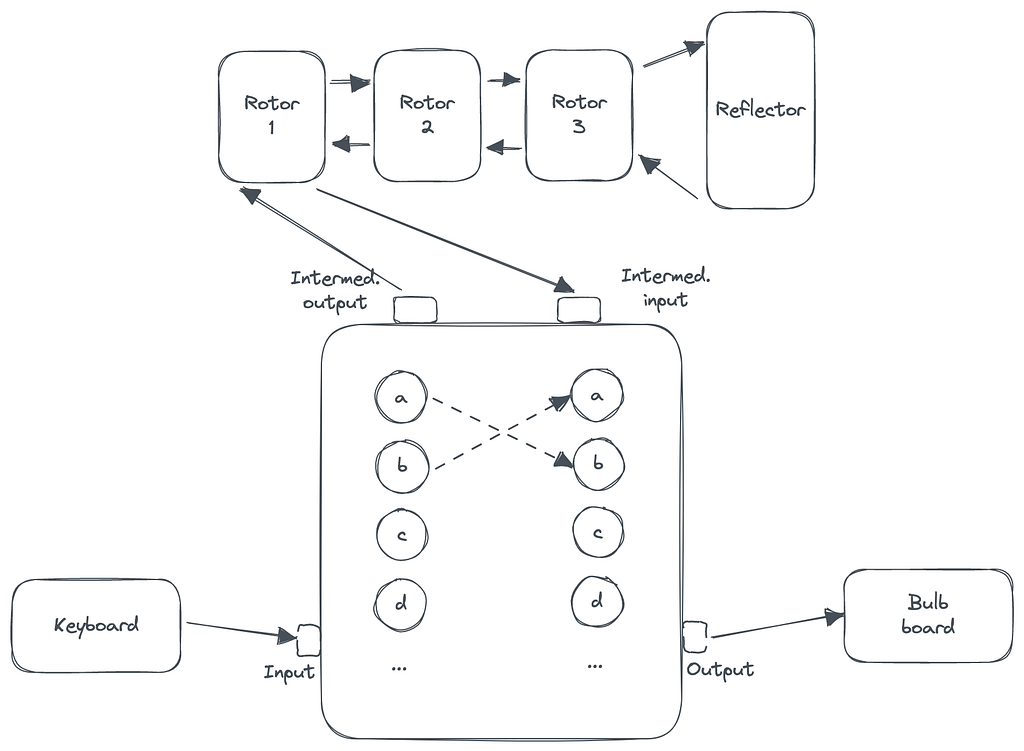
Before we go further, let’s peel the layers of this machine. The interface is simple. You look up today’s configuration from a sheet and set up your machine. Once done, if you want to encrypt a message, you type the letters one by one and note the corresponding letters that light up, constituting an encrypted message. You then transmit this message by whatever channel. When you receive one of these messages, you prepare the machine again by looking up the configuration from your sheet and then start typing the encrypted message noting the characters that light up to get the original plaintext back.
Underneath this simple interface is a clever electro-mechanical circuit with three main components — a switchboard with ten symmetric key substitution switches (e.g. an L with a K and K with an L), three rotors to be chosen from 5–8 possible rotors and finally, a reflector. Each rotor has a “seed” configuration that determines the starting position. Once you hit a letter, the rotors will rotate, and the signal will go through 1) the switchboard, which may change the letter with another; 2) the three rotors, each of which will change the letter; 3) the reflector, which will predictably change the letter and finally 4) the switchboard again which may once more change the output letter with another.
Brute Force Approach
The initial setting, which in modern terms can be called an “encryption key”, consists of 3 rotors to be used out of 5–8 total available, the starting position of each rotor between 1–26, and ten pairs of letters to be substituted on the switchboard. Choosing 3 out of 5 is just 60 different possibilities. Twenty-six possible starting positions on these are 17,576 possibilities. So far, that’s about one million different settings which by modern standards is quite manageable. The switchboard allows us to symmetrically replace ten letters with ten other letters leaving six untouched. This gives us about 150 trillion possible configurations (refer to this video for the math). So the total number of keys to try is about a million times that!
Continuing our back-of-the-envelope math, our modern CPUs can easily manage around 3 billion simple operations with a single core in a second. Let’s say it takes about 100 such operations to try to decode a simple message with a given setting. Therefore, a single core can try 30 million configurations in a second. So to try all possibilities, it’ll take us 150 trillion divided by 30, which is 5 trillion seconds: about 160,000 years! Not that it matters much, but the encryption key changes every 24 hours, so brute forcing this wasn’t an option back then and isn’t an option today! Also, if you got lucky and stumbled upon the correct configuration, you’ll need a mechanism to identify the answer as the right one without any human intervention. There are heuristics to do this, but they will take more CPU cycles and add several 0s behind the years needed to decipher this with brute force.
How did they do it?
If you are like me, you probably think that building a machine to compute combinations slowly will do little to solve this problem. This is where you realize the immense value of spending time to really understand your problem. Allied forces had captured some of the Enigma machines during the war, which gave them full access to test these. They realized that one interesting side-effect of the circuitry was that it’d never encrypt a given letter to itself. It may not seem like much, but it opens up many opportunities for known ciphertext attacks which refers to being able to guess the encryption key based on seeing some examples of known text encrypted using that key. In the real world, this isn’t that hard to imagine. You’d expect a “good morning” at the beginning of many early morning messages or text “weather report” in a daily morning weather report. Alan Turing and his team used this known ciphertext vulnerability to build the Bombe machine to break the code.
In the remaining parts of this post, I’ll dive deep into the said vulnerability and how to take advantage of it. It turns out that more things are wrong with the machine, and we can break it without known ciphertext, but we will see that in a future post.
Why couldn’t a character encrypt to itself?
Proving this part is quite simple. The plugboard is useless in this conversation as it maps letters symmetrically, so without the rotors, it’ll always map everything to itself. Without rotation, rotors are just a single letter-to-letter mapping (single because we can reduce the intermediate mappings to just one) which is also symmetric. The reflector, however, will never map a letter to itself. Thus, proving that the letter will never come out the same is trivial in a non-rotating world.
I was initially afraid that the fact of rotation might make this very hard to prove, but then I realized the mechanism for rotation is connected to the keyboard key press. Thus all the rotation happens before any electric current passes through the circuit. We are therefore guaranteed to have the same mapping for both the forward and backward current — which we already proved guarantees that the letter would never come out the same.
Without looking too deeply into this, it seems this flaw would have been fixed if the rotation happened between the forward and backward motion of the current triggered by the reflector rather than the keystroke. However, there may have been practical difficulties in implementing such a thing. Without the mechanical energy of the keystroke, the only other energy source was a low-voltage battery which likely would not have been sufficient to cause the rotations. Even if it were enough, that would have probably depleted the battery too quickly for the machine to be useful on long journeys.
Cracking the code
For this section, we need to be able to use an enigma machine. Unless you have access to a real one, using a simulator is the best way. I have written one in Python, and it’s available on GitHub. The code should be largely self-explanatory and has comments where it slightly diverges from the description in this post. There’s a Readme.md file for instructions to run locally through the command line.
To crack the code using known ciphertext, we have to deduce the body of the following function:
def predict_enigma_config(ciphertext, plaintext)
-> List[RotorConfig, PlugboardConfig]:
Since the returned RotorConfig here includes initial configurations, if this known ciphertext appears in the middle of the original text, we will have to rewind the returned configuration to get the initial config at the beginning of the text. Since the rotations are deterministic, this is easy.
With that in mind, let’s take a running example to understand the algorithm. Let’s say we found the known ciphertext at the beginning of a large encoded message:
Plaintext: HELLOWORLD
Ciphertext: OJWAHLFOZN
Recall that most of the difficulty in brute forcing comes from the plugboard. Trying a million or so rotor settings should be manageable if we simplify the plugboard part. Therefore, we will attempt to reduce the possibilities for plugboard settings as quickly as possible.
Also note that with the same initial setting, you can run symmetric operations between plain and ciphertext, which gives us more data to work with. For example, with the initial setting, you can get O from H and H from O. After one rotation, you can get J from E and E from J etc.
With that in mind, let’s start with L, as it appears four times in our text. At the third rotation, L becomes W. Let’s guess that L is connected to B on the plugboard. When you send B through the rotor on this setting, say we get X. So now we know LB and XW as the plugboard settings consistent with our initial guess. Then we know L becomes A on the fourth rotation. Say B through the rotors gives Y, so we get YA. Next, we know L becomes W on the 6th rotation. Say now B gives A, so the new rule is AW. To recap, our rules are LB, XW, YA and AW. This is bad because the last rule AW is physically non-enforcible as the plugs for both A and W are already occupied. So we need to discard our initial guess of LB.
This is still too slow, as we are making a guess, running some computations to disprove it, and making more guesses. We’ll still take a long time before we get to a guess that works. Now’s the time to present a clever optimization. Within a given setting of rotors, when we guessed LB, we got X through the rotors for the input B. However, we now know that B was the wrong input to pass. This means the real input could be anything from A-Z but B (including L in case it’s not connected to the plugboard). We also know that the rotors can be reduced to a 1:1 mapping from letter to letter where no two letters can be mapped to the same letter based on our earlier discussion. So, there’s no way X could have been the correct answer out of the rotors when you press A. As a result, we can also discard XB, YA and AW as wrong plugboard settings as they emerged from a wrong base assumption, and it’s impossible to start with a different assumption and come to the same conclusion as long as we’re still with the same rotor setting.
Therefore, our algorithm will start with a guess, do a breadth-first-search of all rules we can gather based on the guess, and see if there’s a contradiction. If there is one, we throw away all the rules and make a second guess. If there isn’t any, we store this as a possible solution. With a large enough known ciphertext (or many patches of it), we shouldn’t see this happen too often. We will follow the same logic for all possible starting positions of the rotors and, in the end, decrypt the text with all keys we could not refute; hopefully, anybody who understands the language should be able to figure out the message fairly quickly, even if we haven’t fully figured out all the plugboard settings yet. Even if we produce thousand of such messages in the output, a group of motivated hundred or so individuals can easily divide and conquer it.
Is there a partial solution?
Before we go, let’s understand why I say a partial solution will print a reasonably identifiable text to a native speaker. Say we found the correct rotor configuration — which we will because we will try all of them. The output will still be garbage if we don’t set any plugboard pins correctly. When we correctly put one pin, some letters will be properly positioned, but it may still not be enough. If we put 3–4 correct pins, including some high-frequency letters (remember we prioritize these in our algorithm), the text may look like a somewhat misspelt natural language. We can use this property along with the natural language detection heuristics such as the Index of Coincidence (IoC) to try to decipher enigma code without any known ciphertext.
Conclusion
In this post, we looked at the anatomy of a typical WWII Enigma machine and appreciated that a simple brute-forcing attack is still not possible despite the astounding computing power growth over the last few decades from Moore’s law. We then explored a crucial flaw in the machine and built an intuition for how that exposes it to known ciphertext attacks. Towards the end of the post, we also saw another flaw in the machine that allows us to tell if we are getting closer to a solution. In the next post, we will dive into the code and solve Enigma with and without known ciphertext.